
Tema: Effektiv Power BI rapportudvikling
Lavet af Frederick Jensen, fj@dataon.dk
Dagens låge hjælper dig som self-service bruger til en mere effektiv rapport udviklingsproces. Med self-service bruger menes en person i forretningen som bruger Power BI til at hente data og opstille rapporter. Artiklen hjælper dig med at forstå en struktureret proces, der gør dig i stand til at udvikle rapporter i Power BI mere effektivt.
Ved at strukturere tilgangen til rapportudvikling kan man opnå en effektivere proces frem for tilfældig ad hoc udvikling. Der er overordnet 3 scenarier for rapportudvikling:
A) Rapporten bygger på data som allerede ligger i en semantisk model
B) Rapporten bygger både på data som allerede ligger i en semantisk model og data fra en anden datakilde (f.eks. en Excel fil)
C) Rapporten bygger på data som ikke ligger i en semantisk model (f.eks. en Excel fil)
Denne artikel er rettet mod scenarie C.
Afhængigt af hvilket af de 3 scenarier man sidder i, så ser udviklingsprocessen lidt forskelligt ud. En rapport udvikles overordnet i 7 trin. De første 3 trin er det forberedende arbejde inden man åbner Power BI Desktop og begynder at udvikle løsningen. Hvert af de 7 trin har mange detaljer. Processen er kun beskrevet overordnet i denne artikel for at give en ide om, hvad en struktureret proces indebærer.
Det hele starter dog med et forretningsbehov som også er målet med rapporten. Det kan være dig selv der har et behov eller du hjælper måske en kollega. Det er selvfølgelig vigtigt at behovet er helt tydeligt og afdækket inden man går i gang.
Derefter starter processen:
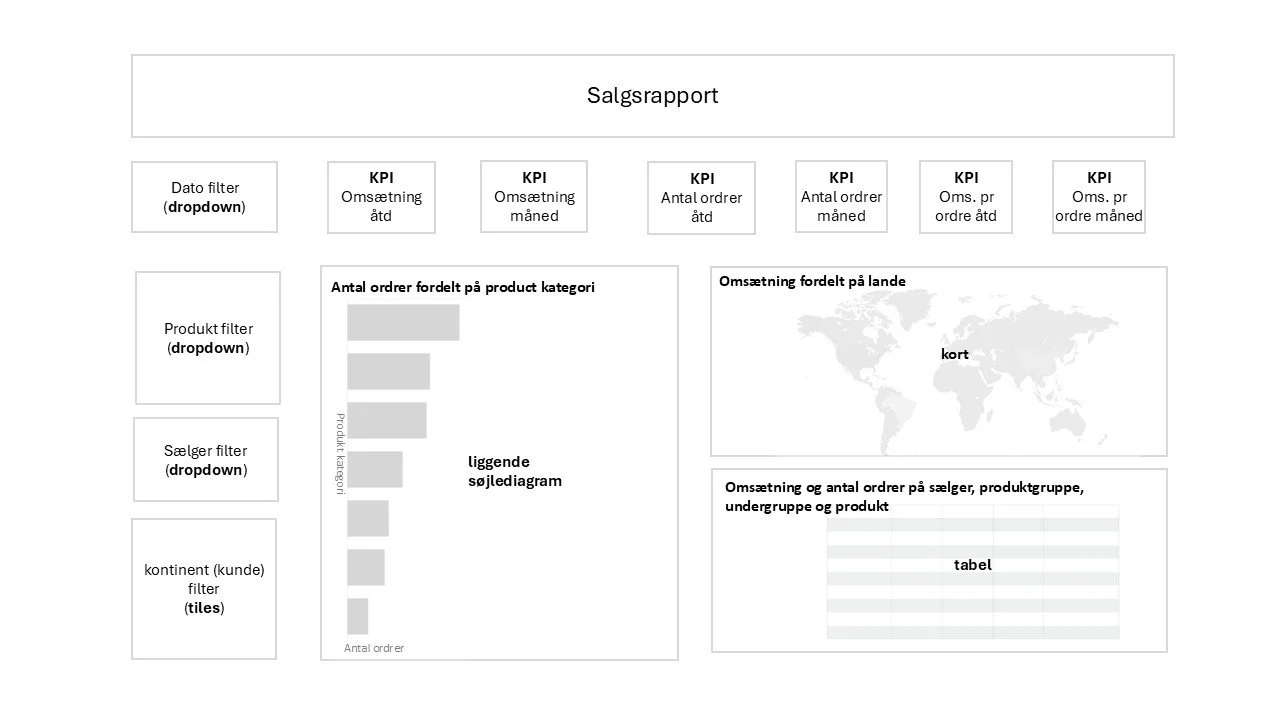
Ad 1) Rapportudkast
Når behovet er beskrevet, laves et udkast til en rapport. Dette udkast ligger til grund for det videre arbejde og bliver målet med opgaven. Det første udkast kan laves hurtigt på en A4-side, hvor man tegner de visualiseringer der skal være på rapporten. Eller man kan bruge PowerPoint, hvor man har forberedt en template med forskellige visualiseringstyper. Visualiseringerne kan hurtigt kopieres ind på en udkastside. Til hver visualisering skriver man de data der skal bruges.
Man kan også bruge forskellige andre programmer til udkastet. Det er vigtigt at det er nemt og hurtigt at lave udkastet.
Se dette eksempel som er lavet i PowerPoint
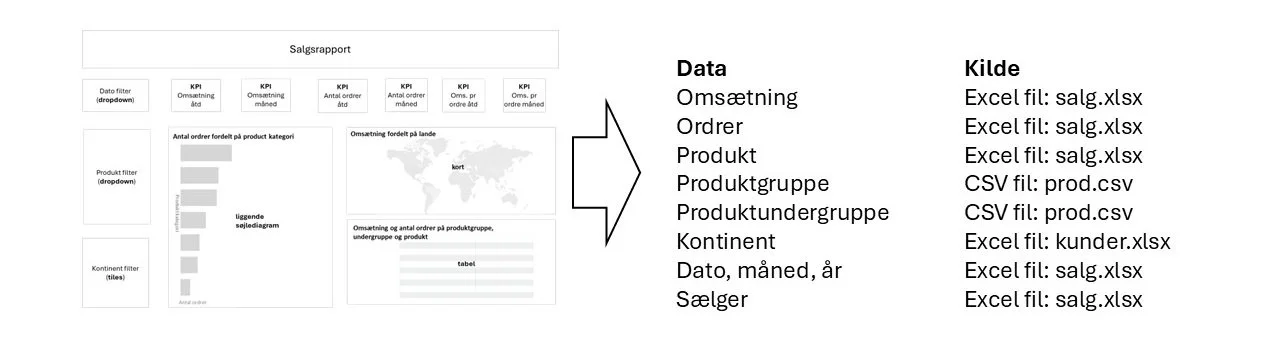
Ad 2) Datakilder
Som self-service bruger, kan datakilder være mange forskellige type: Excel filer, CSV filer, databaser, datawarehouse, semantiske modeller. Hvis man ved, at data ligger i en semantisk model kan man gå direkte til trin 6. Hvis man er usikker på hvor data ligger, så er det afgørende at identificere rapport-scenariet i forhold til hvor data findes:
a) Data ligger i en eksisterende semantisk model, gå til trin 6
b) Data ligger i en eksisterende semantisk model og der er brug for at tilføje egne data, fortsæt nedenfor
c) Data findes ikke i en eksisterende semantisk model, men findes for eksempel i en Excel fil, fortsæt nedenfor
Det kan være en fordel at indlede med at opstilles en liste med de data der skal bruges og angive hvor data findes.
Eksempel:
Ad 3) Design datamodel
Nu er vi kommet til et af de afgørende trin. Det er her den datamodel, som skal understøtte rapporten, defineres. Datamodellen har ikke kun betydning for rapporten men også dataindlæsningen. Dataindlæsningen skal nemlig transformere data så de lander i tabellerne i datamodellen. Datamodellen laves som et stjerneskema med dimensioner og facts. Læs mere om stjerneskema her: https://learn.microsoft.com/en-us/power-bi/guidance/star-schema
Her ses et eksempel på en datamodel som understøtter rapporten fra trin 1:

Ad 4) Data transformation
Her i trin 4 er vi kommet til den del hvor Power BI Desktop skal startes op. I dette trin kopieres data fra kilderne ind i datamodellen. Til dette bruges Power Query. Afhængigt af data kan det være værdifuldt at lave en dataanalyse for at forstå kolonneindholdet og datakvaliteten. Det kan for eksempel være med til at afgøre, hvor der skal indbygges fejlhåndtering.
Nogle gange skal der laves komplekse transformationer og integrationer. I de tilfælde kan det være en ide at skitsere og designe transformationerne inden man går i gang med at bygge dem for at sikre at man har gennemtænkt forløbet.
I Power Query kan det være en fordel at opdele forespørgslerne i forskellige mapper afhængigt af dataforædlingen. F.eks. kan disse mapper bruges: rådata, transformation, integration, datamodel.
Ad 5) Implementering af datamodel
Nu hvor der er indlæst data i tabellerne begynder arbejdet med datamodellen.
Dvs:
· oprette relationer mellem tabellerne (sæt cross-filter direction til single, som udgangspunkt)
· formatere kolonner og sæt default summering
· angive dato tabel
· sæt sortering på kolonner (fx månedsnavn)
· skjule kolonner som ikke skal bruges
· opret en separat tabel til beregninger for at samle beregningerne et sted
Når ovenstående er på plads, begynder en af de teknisk svære dele af arbejdet med rapporten, nemlig at oprette beregninger med DAX. Opret beregningerne i den separate beregningstabel, så de er samlet et sted. Inddel beregningerne i foldere for at skabe overblik.
Ad 6) Rapport
Data er indlæst i tabellerne og datamodellen er på plads. Nu kommer vi til den kreative del, hvor rapporten skal opbygges. Her kommer rapport udkastet fra trin 1 i spil. Den er et godt udgangspunkt for at lave rapporten.
Det ligger uden for denne korte guide at komme ind på rapport opbygning. Man kan med fordel anvende visuelle principper, som f.eks. ensartede farver, tydelige etiketter og en logisk struktur for at gøre rapporten let at forstå og husk ”less is more”.
Ad 7) Publicering
Når rapporten er udviklet, skal den publiceres til Power BI Servicen, hvor den deles med andre. Det kan være en ide at publicere den til et testarbejdsområde hvor den kan testes inden den lægges i produktion. Ved at gøre dette sikrer man, at eventuelle fejl eller mangler kan opdages og rettes, inden rapporten når et bredere publikum. Desuden kan man løbende opdatere og forbedre rapporten baseret på brugerfeedback efter publiceringen.
Nu er rapporten klar til brug. Processen ovenfor består af 7 trin. Undervejs kan der være behov for at gå tilbage til tidligere trin og justere, da forretningsbehov kan ændre sig og man bliver klogere på data. Processen hjælper med at arbejde effektivt omkring rapportudviklingen, da den sikrer en struktureret fremgangsmåde frem for tilfældig ad hoc-udvikling. Ved løbende at reflektere over behov, tilgængelige data og rapportens design kan man sikre, at rapporten altid tilfører reel værdi.