Tema: Power Query Error handling
Lavet af Oscar Minor Jensen, omj@dataon.dk
(udgangspunktet er taget i Reza Rad’s fremgangsmåde)
Dagens låge handler om error handling i Power Query. Hvem har ikke prøvet at opdatere data og, så fejler indlæsningen fordi 1 række ud 100.000 indeholder et ugyldigt datoformat. Egentlig ville man helst indlæse alle gyldige rækker og så håndtere de fejl der måtte være bagefter.
Formålet med dagens låge er at lave en guide for at vise hvordan man kan håndtere et datasæt der indeholder fejl i Power Query. Og hvordan man kan adskille disse fejl fra den brugbare data.
Ideen med denne metode er at skille dataforespørgslen op i to nye dele: en del der ikke indeholder nogen fejl og en anden del der kun indeholder fejl og derfra udtrække information om disse fejl.
Ved at udtrække information omkring fejlene giver det også mulighed for brugeren at se hvor og hvorfor fejlen er opstået, inde i selve rapporten.

Datasættet jeg har anvendt er en CSV fil hentet fra Kaggle: https://www.kaggle.com/datasets/manjeetsingh/retaildataset?resource=download
Jeg har selv manuelt indsat fejl i CSV filen for at skabe fejl i dataindlæsningsprocessen.
Herunder er en skridt-for-skridt fremgangsmåde, for denne fejlhåndteringsprocess.
1. Lav en ny Power BI Desktop fil
2. Hent data fra kilde som indeholder fejl, Bemærk beskeden om fejl:
3. Gå ind I Power Query (Transform Data)
4. Omdøb datakilden I forespørgselsoversigten til ”filnavn – original” (erstat filnavn med forespørgselsnavn der giver mening for datasættet, i mit tilfælde: sales-data-set)
5. Lav derefter to referencer til denne forespørgsel.
6. De to nye forspørgsler skal omdøbes til ”filnavn” og den anden til ”filnavn – fejlhåndtering”.
7. Vælg forespørgslen ”filnavn” og via tabel transformation, vælg ”Remove Errors”.
8. Vælg forspørgslen ”filnavn – fejlhåndtering” og via tabel transformation vælg ”Keep Errors”.
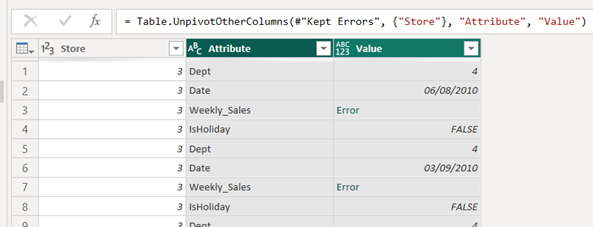
9. Da disse fejl kan forekomme i alle kolonner i tabellen, er det vigtigt at vi vælger ”UnPivot” data.
10. Vælg derfor nøglekolonnen i tabellen, højreklik og vælg ”UnPivot Other Columns”
11. Nu har du de kolonner i din tabel du skal bruge for at håndtere de fejl der må opstå i tabellen: nøglekolonnen, Attribute (indeholder navnene på de kolonner der havde fejl) og Values (fejlkolonnen).
12. Omdøb attributkolonnen til ”Kolonnenavn” og vælg derefter ”Value” og vælg ”Keep Errors”.
13. Nu burde du have en tabel der kun indeholder de rækker og kolonner der indeholder fejl fra hovedkilden (filnavn).
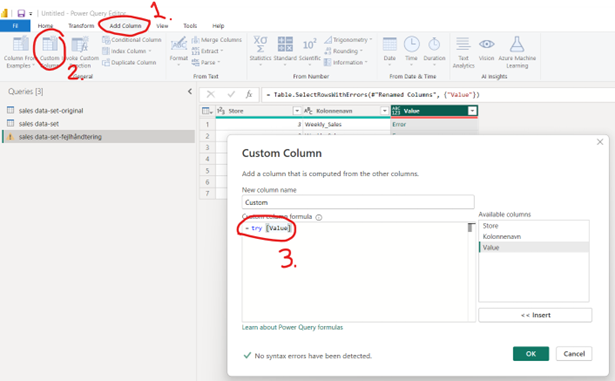
14. Tilføj en ”Custom Column”, altså en brugerdefineret kolonne og gør følgende:
15. ”try” udtryket bruges til fejlhåndtering og konverterer værdier og fejl til en ”Record” værdi. I tilfælde af fejl (som vi kun har i denne forespørgsel) vil denne ”Record” indeholde værdierne for denne ”Error Record”. Med disse værdier kan vi se mere information om hvad fejlen er og hvorfor fejlen er opstået.
16. Den nye kolonne vil have en ”Record” i hver celle. Tryk på ”udvid kolonne”, men vælg kun muligheden ”Error” fra denne udvidelse og tryk OK.
17. Igen vil den nye kolonne vil have endnu en ”Record” i hver celle. Udvid denne kolonne og sørg for at ”kolonne prefix” er tilvalgt for denne for denne udvidelse.
Det er i denne udvidelse, at du kan se nærmere information om fejlene i din data.
18. Nu skal du fjerne ”Value” kolonnen.
19. Det endelige output for disse skridt burde nu give to tabeller, som begge refererer den originale forespørgsel og fordeler rækker i fejl og ikke-fejl, så man altid kan indlæse data.
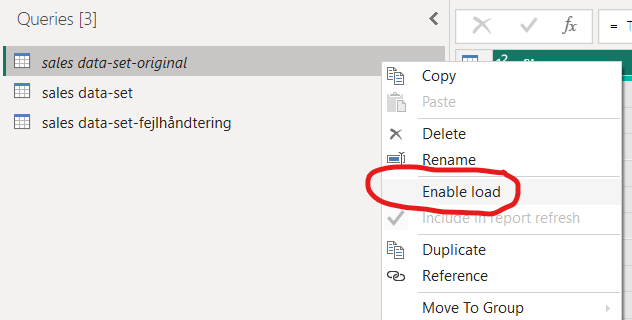
20. Vælg den originale forespørgsel og fjern ”Enable Load”, så da rå data i denne forespørgsel ikke bliver indlæst, når du trykker ”Close and Apply”. På denne måde fungerer denne forespørgsel kun som en reference til de to andre forespørgsler.
21. Du har nu mulighed for at visualisere data i din fejl tabel i din rapport for at informere brugeren af rapporten om eventuelle fejl i data. Dette kan både være en optælling af antal fejl, men også et mere detaljeret billede af hvorfor fejlen er opstået kan også illustreres da vi også har tilvalgt denne information i vores forespørgsel.
22. Herunder har jeg illustreret fejlbeskederne på deres egen fejlhåndteringsside, man kan fx også lave en measure der bare tæller rækker i fejltabellen, for at give brugeren ide om omfanget af de fejl der eksisterer i datasættet. Her fremgår det at fejlene i datasættet skyldes en indtastning der har lavet rod i datatyperne.
De to første kolonner viser hvilken kolonne fejlene er opstået i og hvad fejlen er.